Time Sensitive: A blog about historical research and digital tools.
Zotero, Tropy, and Airtable
I never really loved dishwashers. One of the few things that gives me some sense of control over the chaos of life is washing my dishes. I take my time and choose the order, the pace, and the method I will use to get everything clean and dry. I was highly skeptical of Zotero when I first heard about it. And part of me thinks that this is because I like doing my footnotes the same way I like doing my dishes: calmly and one by one. Digital tools focused on research organization like Zotero disrupt my sense of control over the work. Although it is still my job to make sure primary and second sources are organized and effectively stored in database and directory schemas, these tools cut in half the time spent on the dishes of academic work. In this page, I will talk about the effectiveness of Zotero, Tropy, and AirTable as research tools that can improve the historical work of organizing, interpreting, and analyzing sources.
Zotero
I am yet unsure if I can totally incorporate Zotero into my scholarly practice. But the day has come when I finally give it a try. I started exploring Zotero’s interface and understanding its organizational structure. It seems like the software has come a long way to get things prettier and more user friendly since the last time I looked at it myself – probably, a couple years ago. For my exploration, I downloaded some of my PDF files that I keep on Google Drive, the main cloud platform I have been using for work and study for the past ten years. Since I have always been paranoid about file names and organization, I’ve learned to be consistent with how I save my data and historiographical references. This surely put me in an advantageous position with Zotero.

The platform relies on a familiar directory structure: files are organized in a hierarchy of folders that are here called Collections. All the Collections are hosted in the “My Library” main directory. This familiar structure made it easy for me to replicate the organization of my Google Drive files in Zotero. So, as a first try, I created Collections for each of my courses this semester: Digital History, Urban History, and Legal History – which, lucky me, easily translate to larger fields of the discipline.

I soon noticed that Zotero will automatically enter proper metadata for most PDF files I uploaded to the platform. Those PDFs that were not given an automated metadata were likely downloaded from unreliable online sources (shhh). But the good news is that it was also not hard at all to enter the metadata for those files myself. If anything, the only hard thing was to try to be consistent with dates – you don’t want some of the files to have “02/2015” and others “2015” in the date field. And since each file comes with its own metadata protocol, it is still up to the user to remember to go in and make changes when necessary for the sake of consistency.

One of the main things I want to explore more in Zotero is its notes feature. I am used to reading and marking PDFs in Adobe programs while simultaneously taking notes in Word, precisely because I had never encountered a program in which doing both things was easily achievable. I feel it could even improve my focus and my time management skills, which are obviously mandatory weapons to survive graduate school.
Like many other digital tools for humanities, Zotero is built on JavaScript and SQL languages. It has been around since 2006 and it is no news for many scholars in humanities and social sciences.
Tropy
In the summer of 2021, I did my first solo research trip. With little time to prepare, I had one major goal to accomplish while in Chicago: to take as many pictures of historical records as I could. I had two days to visit the Chicago Public Library where most of the materials relevant to my research topic were located. Luckily for me, Senior Archival Specialist Michelle McCoy kindly separated the collections of my interest. Still, I wish I knew then what I know now.

A few years ago, the Roy Rosenzweig Center for History and New Media (RRCHNM) at George Mason University came up with a digital tool meant to increment humanities researchers’ approach on organizing and managing photographs of research materials. Tropy would have been such a great resource for me back in Chicago. Now jointly developed by RRCHNM, the Luxembourg Centre for Contemporary and Digital History (C²DH), and Digital Scholar, Tropy is free and open-source. It enables a new form of file organization for photographs that is particularly interesting for historical research. To experiment with it, I decided to upload some of my photographs that currently live poorly organized in Google Drive to Tropy.

If you compare the first and the second screenshots, you might feel a sense of relief. Better, right? Tropy is designed in a way that allows for multiple photos to be merged into one group. Then, you can edit the metadata for that group of photographs. In fact, one of the advantages of the application is how it handles metadata for the items. The user can opt between a generic schema, a more precise schema for correspondence items, and the Dublin Core schema, the most widely adopted metadata schema for web resources.

If I knew about Tropy back then, the metadata for those files would have been even more accurate. Tropy generic metadata schema has fields for collection, box, and folder numbers, as well as an identifier (URL or library-assigned call number) for each item. I was able to retrieve some of this information by looking back at the Chicago Public Library’s finding aid. But certainly, Tropy metadata schema works better if the researcher knows how to keep track of the consulted records and their original location in the archive – something very important to uncover intangible information about the archival logic that underpins every historical record.
Another good reason for historians to use Tropy is the application’s notes feature. Transcribing historical records can often be an unpleasant task, especially when it comes to reading old handwritten documents and correspondence. Notes on Tropy are attached to their parent items. Besides reading a document and transcribing it in the same window, it becomes easier to double-check for errors in the original record if necessary.

When I did my second research trip to Saint Louis, Missouri, I was a little more prepared. I used a scanning app that automatically merged my photos as one item and uploaded it to Google Drive. The records I acquired from the Missouri Historical Society and the Saint Louis Public Library were surely more organized than the ones I accessed in Chicago. But none of them had proper metadata. The scanning app named the Saint Louis files as “Scan Nov 13, 2021 at 4.29 PM” and so on. In both cases, it was troublesome to properly reference those records when writing the analysis. Finding information within the PDF files with no metadata was even more complicated. And lastly, transcribing was an issue for most handwritten documents. Next time packing for a research trip, I’ll remember Tropy.
AirTable
Dr. Amanda Regan, my supervisor and co-director of the digital mapping project Mapping the Gay Guides, first introduced me to AirTable when I started to work as a research assistant in the project. Since Mapping the Gay Guides depends on the collaborative work between many researchers and graduate students from California State University at Fullerton to Clemson University, AirTable serves us well as a cloud-based database platform. AirTable is a relational database that allows for a unified workflow and data management system between different parties in a collaborative project like MGG.

Working with the MGG Project provided me with a practical overview of what the platform can offer. In historical research, transforming information into data is an important step to develop digital scholarship that relies on computational processes and algorithmic thinking. One of my first tasks as a research assistant was to transcribe data from Bob Damron’s original guides from 1981 to 1985. I transcribed over 200 records for the U.S. Territories (Virigin Islands, Puerto Rico, and Guam) into a base in AirTable following its data schema.
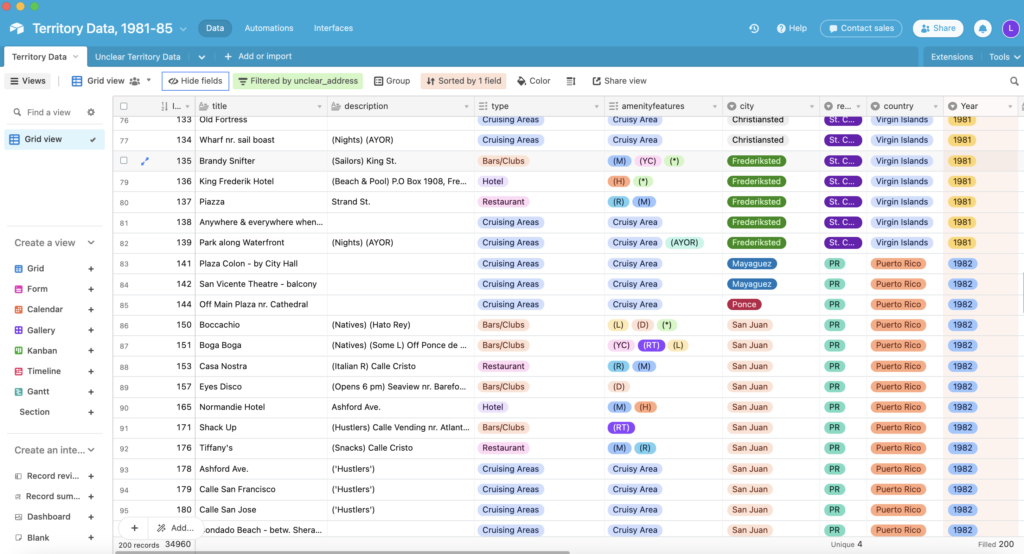
The data structure in AirTable works in a way that fields are interrelated through linked records, making it a very useful relational database. In the example above, each record is an unclear address of Bob Damron’s Gay Guides in the U.S. Territories, and fields reflect the information from the Guides transcribed in form of data. Since the MGG Project involves so many collaborators from different areas, we use the controlled vocabulary feature of AirTable to ensure data integrity when transcribing and entering records into the bases. This is likely one of the most powerful features of the platform. Differently from common Excel spreadsheets, AirTable’s controlled vocabulary makes it easy to track misspelling errors. For example, one cannot enter “cruisy areas” as an amenity feature for a location without having it spelled exactly like “Cruisy Area” as the predefined option for the field. Otherwise, AirTable will notify the user that a new option of category was created, and if not intentional, it should be removed from the list.

As a historian, I am always looking for ways to improve consistency throughout my methodological choices. When I was working for the Geospatial Centroid at Colorado State University, I faced the challenge of mapping more than 200 locations for a project with the Larimer County Department of Natural Resources. In that occasion, when I still had not heard of AirTable, I used an Excel spreadsheet to transform the information of each of those locations into consistent data before geolocating them and making a Web Map with particular attributes for each feature. The result, as you can imagine, was messy. Without a controlled vocabulary feature, the spreadsheet contained multiple inconsistencies throughout the entries.
Another obstacle was not being able to assign one particular record multiple categories in the same field. For that particular project, I was assigning each of those entries particular categories according to the procedures and criteria of the Department of Natural Resources. Some entries, however, fell into multiple categories. In an Excel spreadsheet, there is not an easy way to enter multiple values in the same field besides manually differentiating them with an ordinary separator like semicolon.


AirTable is not a solution for every problem in data consistency and integrity assurance, but it provides digital historians with more functionality to work on their data. Transforming historical information into data is the first step for many digital historians who seek to visualize and analyze information in less traditional ways, and it requires consistent methodological rigor. Zotero, Tropy, and AirTable could be the preliminary toolbox of historians who are hoping to become more familiar with digital humanities approaches and the idea of looking at data (or capta) instead of simply textual information. These tools meant the start of a whole new way of working and scholarly practice for me. And I’m excited to see how my own practice changes in the course of the next five years while I pursue a Digital History Ph.D. degree.
Want to share about a specific tool? Check out each tool’s blog post at the Time Sensitive.